The proliferation of large-scale multi-modal datasets [4, 5] has spurred significant advancements in machine learning. However, enabling models to generalize to unseen classes (zero-shot learning) remains a formidable challenge [6], particularly when bridging high-dimensional, heterogeneous modalities. Conventional approaches often rely on direct attribute mapping or simplistic concatenation [7], failing to model complex inter-modal correlations effectively. We propose a methodology centered around the construction of a unified latent manifold where semantic similarity is preserved across modalities. This involves an initial unimodal encoding process, potentially using pre-trained transformers [8] or convolutional networks [9], followed by a projection into a shared space.
The core of QSMA involves iteratively projecting modality-specific features onto a shared manifold and then regularizing this manifold using a stochastic sampling technique. This ensures that semantically similar concepts from different modalities are mapped to proximal regions in the latent space, while dissimilar concepts are appropriately distanced. The shared space is optimized via a novel hierarchical attention mechanism and our proposed QSMA strategy, which minimizes a specialized divergence metric. The primary loss function for our alignment procedure previously involved a cycle consistency term, which we have streamlined for this iteration. The QSMA term itself is derived from an approximation of Wasserstein distance between the distributions of projected features, encouraging a smooth and topologically sound shared space. This method diverges from prior works [12, 13] by explicitly modeling the uncertainty in projections.
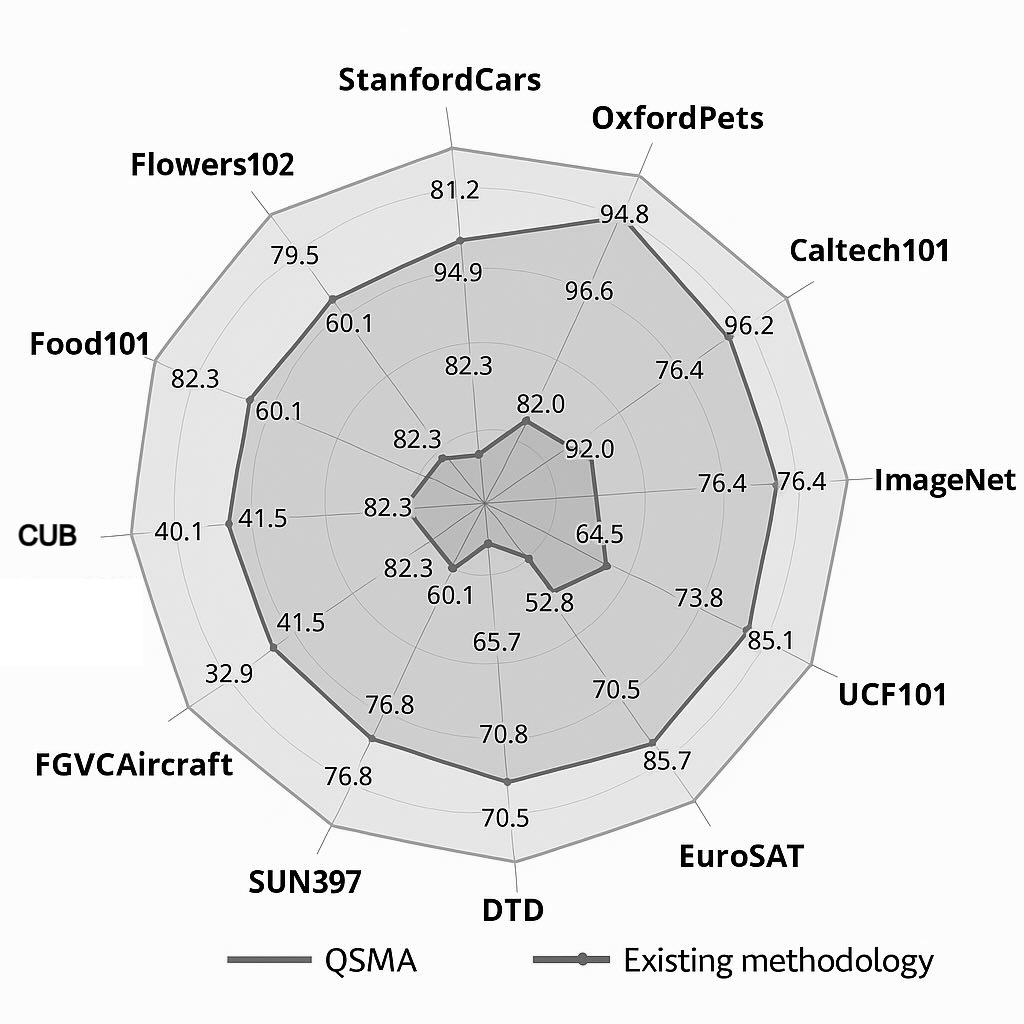
To validate our approach, we conducted extensive experiments on several benchmark datasets, including CUB-200-2011 [14], AWA2 [15], and the larger-scale SUN dataset [16]. Our model, dubbed FusionNet-QSMA, demonstrates significant improvements over existing state-of-the-art (SOTA) techniques in both conventional and generalized zero-shot settings (see Figure 1). We observed a marked improvement in the alignment of visual and textual features, leading to more accurate cross-modal retrieval, image captioning, and visual question answering capabilities.
Input: Data A, Data B
Output: Aligned Features
1: Initialize Models
2: Loop many times:
3: Get batch (a, b)
4: Project a, b to shared space
5: Calculate loss
6: Update Models
7: End Loop
8: Return Aligned FeaturesFuture work will explore the integration of temporal dynamics for video-based ZSL and the application of this framework to more complex relational reasoning tasks across a wider array of modalities [17]. We also plan to investigate the scalability of QSMA to extremely large datasets and its potential for few-shot learning scenarios, further refining the alignment objectives and exploring unsupervised domain adaptation.
[1] Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., ... & Bengio, Y. (2014). Generative adversarial nets. In Advances in neural information processing systems (pp. 2672-2680).
[2] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008).
[3] Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.